
|
latest release v1.8.11 - last update Sun Aug 15 2021 |
Doxygenの内部Doxygenの内部このセクションは、まだ製作中です。 次の図では、ソースファイルの処理の流れを示しています。 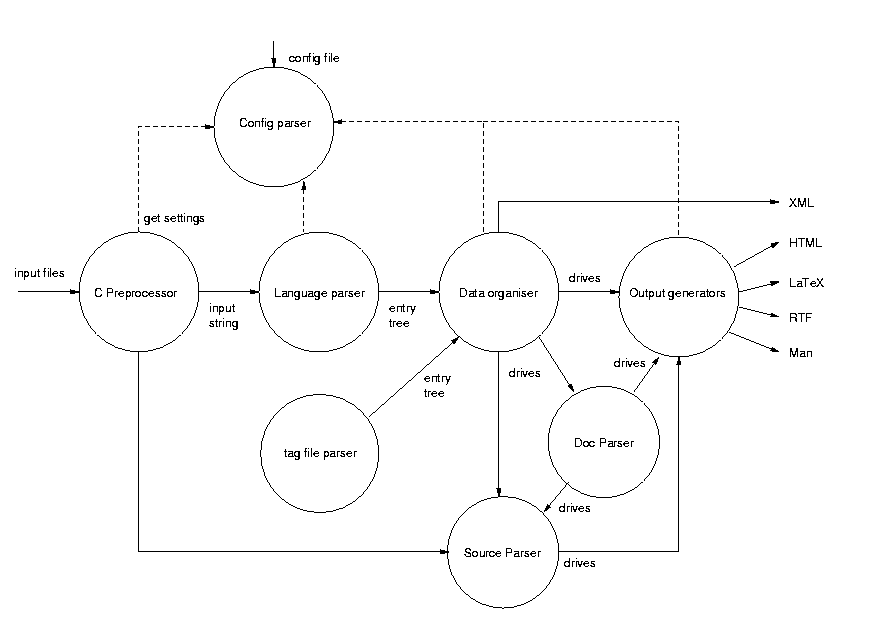
Data flow overview 以下のセクションでは、各ステップを詳しく説明します。 設定の解析プロジェクト設定を制御する設定ファイルを解析し、その結果を 各設定オプションには、次の5つのタイプがあります。
C プリプロセッサ設定ファイルで指定された入力ファイルは、デフォルトで、Cプリプロセッサに任されます(ユーザー定義のフィルタがあれば、まずそれを通します)。 プリプロセッサの処理方法は、標準のCプリプロセッサとは少し違います。 デフォルトでは、マクロ展開をしません。ただし、すべてのマクロを展開するように設定を変えることはできます。典型的な使用法は、ユーザー定義のマクロを展開するだけのことです。この方法は、例えば、関数パラメータのタイプにマクロ名を出現させるなどといったことに使います。 あと一つの違いは、 プリプロセッサは プリプロセッサは、ファイルごとに 0x06 ファイル名 1 0x06 プリプロセスされた、ファイル1の内容 ... 0x06 ファイル名 n 0x06 プリプロセスされた、ファイルnの内容 言語パーサープリプロセスされた入力バッファは、言語パーサーに与えられます。言語パーサーは、 パーサーの役割は、入力バッファを木要素(基本的に抽象的なシンタックスツリー)に変換することです。要素は、 将来の改善に向けて可能なこと
データのまとめこのステップには、多くの小さなステップがあり、取り出したクラス、ファイル、ネームスペース、変数、関数、パッケージ、ページ、グループの辞書を構築します。辞書を構築するほかに、取り出した要素間の関係(継承などの)を計算します。 各ステップには、 このステップでは、たくさんの辞書を出力します。辞書は、 タグファイルパーサータグファイルが設定ファイルに指定されていると、SAX ベースの XML パーサーが解析します。このパーサーは、 ドキュメントパーサー特殊コメントブロックは、それらで記述されるエンティティーに、文字列として格納されます。文字列には、要約説明と、詳細説明があります。ドキュメントパーサーは、これら文字列を読み込み、中で見つけたコマンドを実行します(これが、ドキュメント解析の第2段階です)。結果は、直接、出力ジェネレーターに書き込まれます。 パーサーは、C++ で書かれており、src/docparser.cpp にあります。パーサーが読み込むトークンは、 src/doctokenizer.l が作ります。コメントブロックで見つかったコード断片は、ソースパーサーに渡されます。 ドキュメントパーサーへのメインの入り口は、 ソースパーサーソースブラウジングが有効だったり、ドキュメントにコード断片がある場合、ソースパーサーが起動します。 コードパーサーは、ドキュメント化されたエンティティーと、解析するソースコードとのクロスレファレンスを作成しようとします。ソースのシンタックス強調も行います。出力は、直接、出力ジェネレーターに書き込まれます。 コードパーサーのメインの入り口は、 出力ジェネレータデータを集めて、クロスリファレンスを作成した後、doxygen は、さまざまなフォーマットで出力を生成します。この目的のため、抽象クラス 実際の出力ジェネレータそれぞれに対する出力に書き込まれる内容に、少し違いを出そうとするには、一時的にあるジェネレータを無効にすることで可能です。そのため、OutputList クラスには、 集められたデータ構造からは、XMLが直接生成されます。将来、XML は中間言語(IL)として使われることになるでしょう。出力ジェネレーターは、このILをスターティングポイントとして、特定の出力フォーマットを生成するのに使うでしょう。IL を持つことの利点は、さまざまな言語で独立して書かれた開発ツールが、XML 出力から情報を取り出すことです。そのようなツールとして以下のようなものがあるでしょう。
デバッグdoxygen は、 与えられたflexファイルのためにデバッグ情報を切り替える作業を簡単にするため、次の perl スクリプトを書きました。 #!/usr/bin/perl
$file = shift @ARGV;
print "Toggle debugging mode for $file\n";
if (!-e "../src/${file}.l")
{
print STDERR "Error: file ../src/${file}.l does not exist!";
exit 1;
}
system("touch ../src/${file}.l");
unless (rename "src/CMakeFiles/_doxygen.dir/build.make","src/CMakefiles/_doxygen.dir/build.make.old") {
print STDERR "Error: cannot rename src/CMakeFiles/_doxygen.dir/build.make!\n";
exit 1;
}
if (open(F,"<src/CMakeFiles/_doxygen.dir/build.make.old")) {
unless (open(G,">src/CMakefiles/_doxygen.dir/build.make")) {
print STDERR "Error: opening file build.make for writing\n";
exit 1;
}
print "Processing build.make...\n";
while (<F>) {
if ( s/flex \$\(LEX_FLAGS\) -P${file}YY/flex \$(LEX_FLAGS) -d -P${file}YY/ ) {
print "Enabling debug info for $file.l\n";
}
elsif ( s/flex \$\(LEX_FLAGS\) -d -P${file}YY/flex \$(LEX_FLAGS) -P${file}YY/ ) {
print "Disabling debug info for $file\n";
}
print G "$_";
}
close F;
unlink "src/CMakeFiles/_doxygen.dir/build.make.old";
}
else {
print STDERR "Warning file src/CMakeFiles/_doxygen.dir/build.make does not exist!\n";
}
$file = shift @ARGV;
print "Toggle debugging mode for $file\n";
# add or remove the -d flex flag in the makefile
unless (rename "Makefile.libdoxygen","Makefile.libdoxygen.old") {
print STDERR "Error: cannot rename Makefile.libdoxygen!\n";
exit 1;
}
if (open(F,"<Makefile.libdoxygen.old")) {
unless (open(G,">Makefile.libdoxygen")) {
print STDERR "Error: opening file Makefile.libdoxygen for writing\n";
exit 1;
}
print "Processing Makefile.libdoxygen...\n";
while (<F>) {
if ( s/\(LEX\) (-i )?-P([a-zA-Z]+)YY -t $file/(LEX) -d \1-P\2YY -t $file/g ) {
print "Enabling debug info for $file\n";
}
elsif ( s/\(LEX\) -d (-i )?-P([a-zA-Z]+)YY -t $file/(LEX) \1-P\2YY -t $file/g ) {
print "Disabling debug info for $file\n";
}
print G "$_";
}
close F;
unlink "Makefile.libdoxygen.old";
}
else {
print STDERR "Warning file Makefile.libdoxygen.old does not exist!\n";
}
# touch the file
$now = time;
utime $now, $now, $fileflexコードから、ルールに適合するあるいはデバッグ情報を得るには、もうひとつ、cmakeにLEX_FLAGSを適用する方法があります。
|
|
|
This page was last modified on Sun Aug 15 2021.
© 1997-2021 Dimitri van Heesch, first release 27 oct 1997.
© 2001 OKA Toshiyuki (Japanese translation). © 2006-2021 TSUJI Takahiro (Japanese translation). © 2006-2014 TAKAGI Nobuhisa (Japanese translation). |