
|
latest release v1.8.11 - last update Sun Aug 15 2021 |
目次外部インデックスと検索はじめにバージョン1.8.3で、doxygenは外部インデックスツールと検索エンジンを使ってHTMLを検索できるようになりました。 これには、いくつか利点があります。
自分でインデックス作成や検索エンジンを書かなくてよいように、doxygenは、各アクション用のサンプルツールを提供します。データインデックス作成には データの流れを以下の図に示します。 
外部検索でのデータの流れ
設定最初のステップは、ウェブサーバーを通して検索エンジンを使えるようにすることです。 ウェブサーバーのセットアップ方法は、このドキュメントの範囲外です。しかし、Apacheをインストール済みであれば、doxygenの
http://yoursite.com/path/to/cgi/doxysearch.cgi?test 次のようなメッセージが出るはずです。 Test failed: cannot find search index doxysearch.db Internet Explorer であれば、ファイルをダウンロードするよう促され、このメッセージが出ます。 doxysearch.db は作成もインストールもしていないので、テストが失敗するのはこのためです。これを修正する方法は、次のセクションで説明します。 次のセクションに行く前に、設定ファイルで、上のURL( SEARCHENGINE_URL = http://yoursite.com/path/to/cgi/doxysearch.cgi 単一のプロジェクトインデックス外部検索オプションを使うには、設定ファイルで、以下のオプションを有効にしてください。 SEARCHENGINE = YES SERVER_BASED_SEARCH = YES EXTERNAL_SEARCH = YES これで、doxygenは、出力ディレクトリ(OUTPUT_DIRECTORY で設定します)に 次のステップは、生の検索データをインデックスに入れ込み、効率的な検索ができるようにします。この作業には、 doxyindexer searchdata.xml これにより、
http://yoursite.com/path/to/cgi/doxysearch.cgi?test すると、次のメッセージが出ます。 Test successful. これで、HTML出力から単語やシンボルの検索が可能になります。 複数プロジェクトのインデックス複数のプロジェクトがあって、関連がある場合は、どのプロジェクトのドキュメント内からも、すべてのプロジェクトにある単語を検索できるようにするほうがいいでしょう。 これを可能にするには、全プロジェクトの検索データを単一のインデックスに結合することです。例えば、AとBというプロジェクトがあって、searchdata.xml が project_A と project_B ディレクトリに生成されます。そして次のように実行します。 doxyindexer project_A/searchdata.xml project_B/searchdata.xml 次に、その結果できる
それぞれのプロジェクトを識別するには、各プロジェクトに EXTERNAL_SEARCH_ID を使ってユニークなIDをセットする必要があります。 検索結果を正しいプロジェクトにリンクするため、EXTRA_SEARCH_MAPPINGS タグを使って、プロジェクトごとにマッピングを定義する必要があります。このオプションで、他のプロジェクトのIDから、そのプロジェクトのドキュメントの(相対的な)場所へのマッピングを定義できます。 設定ファイル内でのプロジェクトA,Bに関連する箇所は、次のようになります。まずプロジェクトAは、 project_A/Doxyfile ------------------ EXTERNAL_SEARCH_ID = A EXTRA_SEARCH_MAPPINGS = B=../../project_B/html 次にプロジェクトBは、 project_B/Doxyfile ------------------ EXTERNAL_SEARCH_ID = B EXTRA_SEARCH_MAPPINGS = A=../../project_A/html これらの設定により、プロジェクトA,Bは同じ検索データベースを共有できます。そして検索結果は、正しいドキュメント・セットにリンクするようになります。 インデックスの更新ソース・コードを変更したら、doxygenを実行してドキュメントを再度更新しなければなりません。外部検索機能をお使いの場合は、 プログラミング・インタフェース前節までは、インデックスと検索を行うために、 このためには、次の3インタフェースが重要です。
次以降のセクションでは、これらのインタフェースを詳しく説明します。 インデックスツールの入力フォーマットdoxygenが作成する検索データは、Solr XML インデックスメッセージのフォーマットに従います。 インデックスツールの入力は、XMLファイルで、 docノード一つの例を挙げます。一つのメソッドに対する検索データとメタデータが含まれます。 <add>
...
<doc>
<field name="type">function</field>
<field name="name">QXmlReader::setDTDHandler</field>
<field name="args">(QXmlDTDHandler *handler)=0</field>
<field name="tag">qtools.tag</field>
<field name="url">de/df6/class_q_xml_reader.html#a0b24b1fe26a4c32a8032d68ee14d5dba</field>
<field name="keywords">setDTDHandler QXmlReader::setDTDHandler QXmlReader</field>
<field name="text">Sets the DTD handler to handler DTDHandler()</field>
</doc>
...
</add>
各フィールドにはnameがついています。次のようなフィールド名がサポートされます。
検索URLのフォーマットdoxygenが生成するHTMLページから検索エンジンが起動されるとき、たくさんの引数がquery stringを使って渡されます。 次のフィールドを渡します。
検索結果の完全なリストから、 クエリーの例を示します。 http://yoursite.com/path/to/cgi/doxysearch.cgi?q=list&n=20&p=1&cb=dummy この例は、単語'list' (
検索結果のフォーマット前のサブセクションで説明したとおり、検索エンジンを起動すると結果を返却してきます。そのフォーマットは、JSON with paddingで、基本的に関数呼び出しにラップされたjavascriptの構造体です。関数の名前は、コールバックの名前(クエリ内の cb フィールドで渡されます)です。 前のサブセクションで説明した例では、返却の主構造は、以下のようになります。 dummy({
"hits":179,
"first":20,
"count":20,
"page":1,
"pages":9,
"query": "list",
"items":[
...
]})
フィールドの意味を説明します。
items 配列の要素がどのようなものを示す例を挙げます。 {"type": "function",
"name": "QDir::entryInfoList(const QString &nameFilter, int filterSpec=DefaultFilter, int sortSpec=DefaultSort) const",
"tag": "qtools.tag",
"url": "d5/d8d/class_q_dir.html#a9439ea6b331957f38dbad981c4d050ef",
"fragments":[
"Returns a <span class=\"hl\">list</span> of QFileInfo objects for all files and directories...",
"... pointer to a QFileInfoList The <span class=\"hl\">list</span> is owned by the QDir object...",
"... to keep the entries of the <span class=\"hl\">list</span> after a subsequent call to this..."
]
},
このような要素のフィールドには次の意味があります。
|
|
|
This page was last modified on Sun Aug 15 2021.
© 1997-2021 Dimitri van Heesch, first release 27 oct 1997.
© 2001 OKA Toshiyuki (Japanese translation). © 2006-2021 TSUJI Takahiro (Japanese translation). © 2006-2014 TAKAGI Nobuhisa (Japanese translation). |
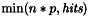
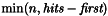
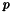
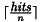 .
.